
La robotique et l’intelligence artificielle (IA) ont ceci en commun de fasciner autant qu’inquiéter le grand public. Pour la plupart des personnes, les deux domaines sont indissociables, l’image véhiculée par le cinéma étant celle d’une machine douée de réflexion.
La réalité est autre à ce jour, la plupart des robots ayant des séquences de comportements entièrement programmées, pré-définies.
Dans le but de voir émerger des comportements plus adaptables, les choses changent, et avec l’augmentation des capacités des unités de traitement, des modes de traitement de l’information, qui été restés longtemps purement conceptuels, voient le jour.
Le 17 décembre dernier, à l’ISIR, à Paris, dans le cadre du Groupe de Recherche en robotique, des chercheurs ont présenté leurs travaux, à l’intersection des deux domaines.
Neurosciences : d’un cerveau (biologique) à l’autre (artificiel)

Erwan Renaudo (ISIR, Université Pierre et Marie Curie, fig. 1) a présenté une architecture logicielle de prise de décision pour les robots autonomes, capable d’apprendre des habitudes. Les capacités du robot à planifier sont conservées. Mais il lui est ajoutée une capacité à former des habitudes.
Actuellement, le comportement d’un robot est déterminé par un « logiciel planificateur » qui calcule quelles actions faire en « réfléchissant » aux différentes possibilités. Cette méthode est coûteuse en termes de calcul et en temps, et elle est utilisée à chaque fois que le robot doit résoudre une tâche. De plus, les connaissances sur le monde utilisées par le robot sont apportées a priori par un humain, et n’évoluent pas en fonction des modifications de l’environnement ou dans la tâche.
M. Renaudo et ses collègues veulent éviter au robot de repayer le coût de la planification lorsqu’il a déjà réalisé cette tâche plusieurs fois. C’est en effet ce que chacun peut constater : quand nous devons répéter une tâche souvent, dans des contextes similaires, elle devient habituelle et nous la faisons presque sans y penser. Le chercheur s’est inspiré d’expériences avec un rat. L’animal doit chercher la sortie d’un labyrinthe. De la même manière, l’expérience est répétée et l’animal apprend peu à peu le chemin vers la sortie. Le labyrinthe est ensuite modifié (par exemple, on change la position de la sortie). Si l’animal a passé un temps moyen à accomplir la tâche, il est capable d’adapter son comportement et trouver rapidement la nouvelle sortie. S’il a passé un temps beaucoup plus long, son comportement est devenu habituel, et l’animal à du mal changer l’adapter aux nouvelles conditions.
Le but du chercheur va donc être de s’inspirer de ces résultats sur le comportement des mammifères pour créer une architecture de contrôle qui soit capable d’apprendre des habitudes ou de revenir à un comportement adaptable quand l’environnement change. Cette architecture utilise des algorithmes d’apprentissage par renforcement.
Pour cela, le logiciel de contrôle comprendra trois parties :
– un « expert dirigé vers un but ». Cette partie du logiciel planifie le comportement en examinant les différentes possibilités et leurs conséquences. Grâce à l’apprentissage par renforcement, la connaissance est apprise au fur et à mesure sans que l’humain ne la donne a priori. L’expert est adaptable mais lourd en calculs.
– un « expert habituel ». Cette partie du logiciel, constituée d’un réseau de neurones, apprend des essais successifs réalisés par le robot (il s’habitue). L’apprentissage est long et peu adaptable, mais choisit le comportement de manière bien moins coûteuse que l’expert « dirigé vers un but ».
– un méta-contrôleur. Cette partie du logiciel doit orchestrer les actions des deux autres. Il sélectionne lequel des deux experts contrôle le robot en fonction du contexte. Afin de valider l’intérêt de cette architecture, une première étude est faite avec sélection aléatoire (fonction random) entre les deux experts.

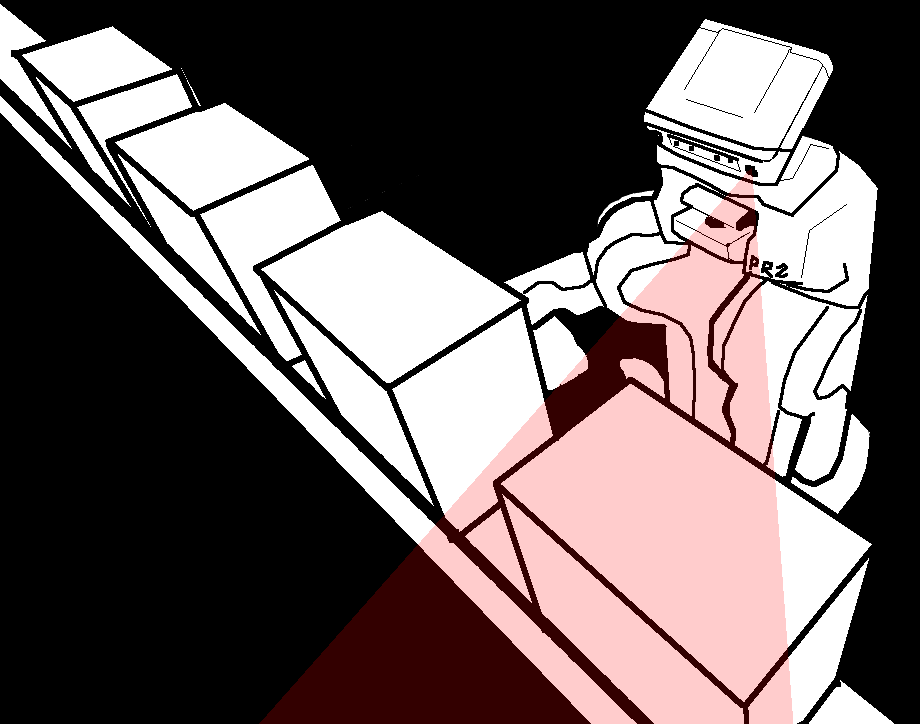
Pour l’expérience, le cas de test simulé est celui d’un robot poussant des blocs sur un tapis roulant (fig. 2). Si le robot parvient à pousser un bloc, il reçoit une récompense, ce qui permet à chaque expert d’apprendre la bonne stratégie.
Quel est le résultat obtenu par ce nouveau modèle ? Dans le cas où l’environnement ne change pas, on voit que l’expert habituel est le plus performant. Il est même alors meilleur que l’expert « dirigé vers un but ». Le modèle complet a une performance moyenne, du fait du mode de sélection, aléatoire.
La vitesse du tapis est alors modifiée. C’est à ce moment-là que le nouveau modèle montre son intérêt : la combinaison des deux experts permet de réadapter très vite le comportement et de garder la même performance sur la tâche, tandis que les deux experts pris individuellement connaissent une « cassure » de leur performance : le comportement doit se réadapter à la nouvelle vitesse.
Ce modèle sera à perfectionner. Ainsi, la sélection aléatoire du meta-contrôleur servira de référence pour tester d’autres critères plus pertinents.
Il est possible de détecter assez simplement lorsqu’une habitude a été apprise (et donc qu’il vaut mieux l’utiliser plutôt que de planifier à nouveau) ou lorsque le comportement n’est plus adapté (et qu’il faut revenir à l’expert « dirigé vers un but », qui est adaptable).
Ce type de méthode aura une application certaine lors de collaborations robot-humain pour s’adapter à un humain peu collaboratif, ou dans les cas où il est nécessaire de s’adapter à des changements d’environnement.
Ce flux d’informations sur lequel baser les actions de nos robots, d’où viendra-t-il ?
Les théories sensorimotrices et les expériences en psychophysique humaine soulignent la nécessité d’un traitement multimodal de l’information (dans le sens de la gestion de multiples entrées et flux de données d’apprentissage).
Mathieu Lefort, post doctorant à l’ENSTA-Paristech, propose un traitement des données inspiré de celui qui a lieu dans le cortex humain.
Il s’agit d’un apprentissage de corrélations spatiales entre les données de diverses entrées, c’est-à-dire les données qui apparaissent de manière simultanée dans les différents flux sensoriels.
Cela peut par exemple correspondre à la vue de quelqu’un qui parle et de l’audition de ses paroles.
Cet apprentissage est :
– non supervisé: le robot n’a pas besoin d’un professeur pour apprendre, comme cela peut être le cas chez l’enfant,
– en ligne: le robot apprend tout au long de sa vie,
– incrémental: quand le robot apprend quelque chose de nouveau, il n’oublie pas ce qu’il avait appris précédemment,
– décentralisé: l’apprentissage est réparti dans plusieurs modules du robot de telle sorte que si un module tombe en panne le robot reste fonctionnel,
– orienté vers une tâche, car, il ne faut pas l’oublier, une tâche est à réaliser.
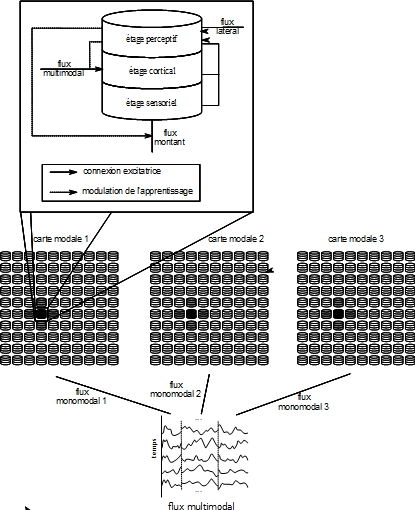
L’architecture de ce modèle ressemble à ce que l’on peut trouver dans certaines structures cérébrales (aires sensorielles bas niveau et colliculus supérieur notamment). Chaque flux d’information est traité par une carte corticale, qui fournit une représentation du stimulus par la position d’une bulle d’activité qui émerge dans la carte (fig. 3). La position des bulles d’activités dans chaque carte est contraint d’être à la même place pour les stimuli qui apparaissent simultanément dans chaque modalité. C’est la principale contrainte de ce modèle : il suppose que les modalités ont des représentations superposables.
[…]
Quelques liens :
– Pages personnelles d’Erwan Renaudo : http://people.isir.upmc.fr/renaudo
– Pages personnelles de Mathieu Lefort : http://perso.ensta-paristech.fr/~mlefort/
[…] L’article dans son intégralité est paru dans Planète Robots n°32 du 1er Mars 2015